When dealing with complex problems is it often useful to start from a toy problem and then build up in complexity. In the context of deep learning this can be achieved in multiple ways. In DeepDIVA, we chose to implement additional support for working on bidimensional data. The advantage of working on bidimensional data is that it can be visualized easily and in general experiments are quick and converge fast.
Running It
For a simple scenario it is only necessary to provide the following parameters:
--dataset-folderspecifies the location of the dataset on the machine--runner-class bidimensionalspecifies to use the code for this task and not the standard image classification one
The runner class is necessary to specify to the system that we want to run on bidimensional data. Note: if the dataset being used starts with bd_ then DeepDIVA automatically sets runner-class=bidimensional
For example:
python RunMe.py --dataset-folder /path/to/dataset --runner-class bidimensional
It is very important that the dataset is in the right structure (see prepare your data).
Troubleshooting:
See Troubleshooting
Visualize Results
In addition to those provided by the image classification (see perform image classification), the following visualizations are produced and can be seen on your Tensorboard. For a full list see full list of visualizations
Classification Output
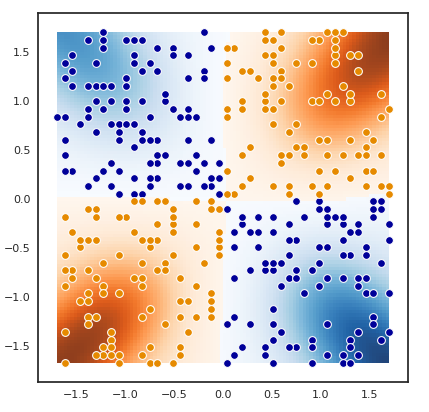
This is a visualization of the decision boundaries of the network. In practice this is realised by asking the model to output a prediction to all points in the grid. The colour of the background represent the output of the model, whereas its intensity the confidence. Strong colour means high confidence, light (more white) colour means low confidence. The points in the foreground represent the samples in the validation set. Their colour reflect the class they belong to.
The following image is an example of a network which learned to solve the continuous XOR problem:
Customization Options
There are a lot of elements that can be modified in an experiment. Many functionalities are already implemented and accessible through a command line parameters.
See customizing options for a brief overview of the most common ones.
For a comprehensive list of the possibilities offered by the framework see the latest version of the docs.